

Slackに投稿された議事録から顧客データや議事録の要約を抽出し、自動でデータベースに登録できたら便利ですよね?
今回ご紹介するのは、Slackの議事録メッセージから必要な情報を抽出・整形し、n8nを通じてAirtableに自動登録するワークフローです。GPT-4による自然言語処理も取り入れており、実運用でも十分に使えるレベルに仕上がっています。
ワークフロー全体の流れ
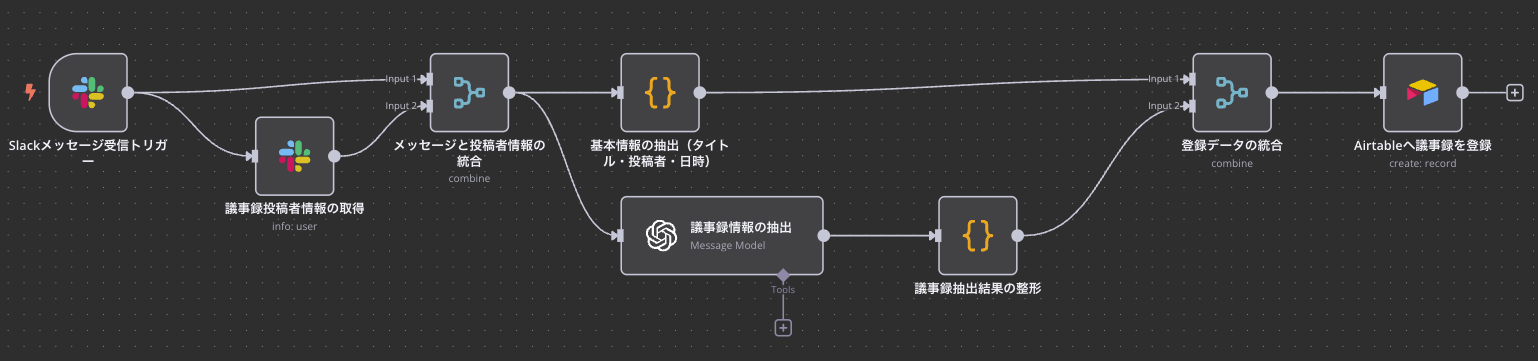
この自動化フローは、次のようなステップで構成されています:
1. Slackメッセージ受信トリガー
Slackの特定チャンネル(議事録チャンネル)に新しい投稿があったとき、自動でワークフローが起動します。
投稿されたメッセージと投稿者のユーザーIDを取得します。
2. 議事録投稿者情報の取得
投稿者のSlackユーザーIDをもとに、Slack API経由で氏名などのプロフィール情報を取得します。
この情報は「誰が投稿したか(owner)」として後から記録されます。
3. メッセージと投稿者情報の統合
Slackから取得した投稿内容と、投稿者のプロフィール情報をひとつに統合します。
この統合によって、1つのメッセージデータとして後の処理で扱いやすくなります。
4. 基本情報の抽出(タイトル・投稿者・日時)
Slackメッセージの1行目を「議事録タイトル」として取得。
あわせて投稿者の名前と、投稿時刻(UNIX秒)をISO形式(例:2025-06-20T10:00:00Z)に変換します。
5. 議事録情報の抽出(GPT-4)
投稿された議事録本文をGPT-4に渡し、以下の項目を自然言語から抽出します:
- ミーティング実施日時(「6/20(火) 10:00〜」など明記されている場合)
- 会社名(クライアント名)
- 担当者名
- 議事録の要約(300文字以内)
- 次に取るべきアクション(TODOなど)
構造化されていないSlackメッセージが、この処理でデータベース向けの形式に変換されます。
6. 議事録抽出結果の整形
GPT-4から返ってきた内容をJSON形式で扱いやすく整形します。```json``` などの囲み記号の除去、曖昧な表現(「特定できません」など)の空文字変換もこのステップで行います。
7. 登録データの統合
「投稿者情報+基本情報」と「GPT-4が抽出した議事録の内容」をひとつにまとめ、Airtableへの登録用データが完成します。
8. Airtableへ議事録を登録
最終的なデータをAirtableに新規レコードとして登録します。
Slackに投稿された議事録が、整理された状態でAirtableに蓄積されていきます。
Airtable側で用意したテーブル
このワークフローで使用しているAirtableテーブルには、以下の8つのカラムを用意しています:
| カラム名 | 説明 |
|---|---|
| meeting_datetime | ミーティング実施日時(本文に日時がある場合のみ) |
| client_name | クライアントの会社名 |
| client_contact_name | クライアント側の担当者名 |
| meeting_title | 議事録のタイトル |
| meeting_summary | GPT-4による要約(300文字以内) |
| next_action | 次に取るべきアクション |
| owner | Slackに議事録を投稿した人の氏名 |
| slack_posted_at | Slackに投稿された日時 |
この構成によって、「いつ」「誰が」「どの会社と」「何を話し」「何をすべきか」が明確に整理され、Airtableでのフィルタ・検索・ビュー切替による活用が可能になります。
おわりに
Slackで共有された議事録が、そのまま行動に活かせるデータとして蓄積されるこの仕組み。
日々の情報共有をスムーズにし、対応漏れや見落としを減らすことができます。
この仕組みはさまざまな業務に応用できます。
「うちのチームでも使ってみたい」「他の用途にも応用できそう」と思った方は、ぜひお気軽にご相談ください!